黃文濤
我們研究某一個母體,例如甲廠牌電視機的壽命,常設定有一個分佈函數,而這分佈函數就是在說明該廠牌出品的某一電視機其壽命(發生故障以前)大於某一段時間的機率。一般而言,這個分佈函數常帶有一個或數個未知參數。所以想瞭解該廠產品的壽命情況,勢必要設法去估計這些未知參數。由取樣(即記錄一些該廠出品電視機的壽命)來估計這些未知參數的問題,稱為統計估計問題,這在統計學上已成為一個專門研究的支系。那麼這些樣本值,如何處理,如何「過濾」,才會濾去不必要而留下那些真正與參數有關的資料,而且在處理或「過濾」過程中,不要遺漏了任何與參數有關的資訊。這就牽涉到充分統計量的概念。諸樣本值的(可測)函數而不帶任何未知量的稱為統計量。若諸隨機樣本的聯合機率函數,在某一統計量給定下之條件機率與某些參數(設稱為乙)無關時,則稱該統計量為這些乙參數之充分統計量。例如甲廠牌出品的電視機壽命一般視為服從指數分佈律,則其諸樣本的算術均數即為該廠牌「所有」產品的平均壽命(即該指數分佈的期望值)的充分統計量,而諸樣本和也是,所以充分統計量並非唯一。
英國著名統計學家 (R.A. Fisher) 在1920年的一篇論文中首先指出了充分統計量的概念,而這個「充分統計量」的名詞卻要到1922年的論文〈On the mathematical foundation of theoretical Statistics〉(論理論統計的數學基礎)才正式出現。實際上,《Nature》雜誌在1921年11月24日出版的摘要中首先出現。
英國天文學家艾靈頓 (A.S. Eddington) 在1914年出版的《星球運動和宇宙結構》一書中提到,對於估計一些觀測值的差誤,取其均值之差量的絕對值和 ( ![]() ) 比一般的差方和 (
) 比一般的差方和 ( ![]() ) 來得恰當,但這卻與一般書上所寫的相反。為著檢驗他的主張,費雪開始作這兩形式的比較研究。他假設由均值為 m,變異數為 (
) 來得恰當,但這卻與一般書上所寫的相反。為著檢驗他的主張,費雪開始作這兩形式的比較研究。他假設由均值為 m,變異數為 (![]() )(m,
)(m,![]() 均為未知參數)的常態分佈母體取 n 個樣本,設依次為 x1,x2,…,xn,以
均為未知參數)的常態分佈母體取 n 個樣本,設依次為 x1,x2,…,xn,以 ![]() 表其樣本平均值。費雪研究了對於參數σ的兩種不同估計量,即
表其樣本平均值。費雪研究了對於參數σ的兩種不同估計量,即 ![]() 與
與 ![]() 。計算這兩個統計量的標準離散度(即變異數的平方根),發現當 n 大時,
。計算這兩個統計量的標準離散度(即變異數的平方根),發現當 n 大時,![]() 之標準離散度比
之標準離散度比 ![]() 大了百分之十四,這與艾靈頓的說法不符(對於某一參數的估計統計量,其變異數愈小愈好,因為這表示其出現值的離散程度愈小)。費雪繼續又證明了基於
大了百分之十四,這與艾靈頓的說法不符(對於某一參數的估計統計量,其變異數愈小愈好,因為這表示其出現值的離散程度愈小)。費雪繼續又證明了基於 ![]() 型式的估計量,當 p=2 時,其變異數為最小。其實,這除了費雪用漂亮的幾何方式證明之外,一點也沒有什麼新奇,因為早在1816年,高斯 (C. Gauss) 已發表了相同的結果。所幸費雪並不就此罷手,他進一步算了 n=4 時的
型式的估計量,當 p=2 時,其變異數為最小。其實,這除了費雪用漂亮的幾何方式證明之外,一點也沒有什麼新奇,因為早在1816年,高斯 (C. Gauss) 已發表了相同的結果。所幸費雪並不就此罷手,他進一步算了 n=4 時的 ![]() 與
與 ![]() 的聯合分佈函數(n 極大時,
的聯合分佈函數(n 極大時,![]() 與
與 ![]() 趨近於常態分佈,所以 n 小時,情況較複雜),而這時他發現了一個極有趣的現象:在
趨近於常態分佈,所以 n 小時,情況較複雜),而這時他發現了一個極有趣的現象:在 ![]() 給定某值之後,
給定某值之後,![]() 之分佈居然與 σ 無關!而另一方面,在
之分佈居然與 σ 無關!而另一方面,在 ![]() 給定某值之下,
給定某值之下,![]() 之分佈函數仍然含有參數 σ。這就說明了在尋找參數 σ 的資訊過程中,若先決定了
之分佈函數仍然含有參數 σ。這就說明了在尋找參數 σ 的資訊過程中,若先決定了 ![]() 值,我們仍然可以用
值,我們仍然可以用 ![]() 來改進其估計值,但是,反過來,若先決定
來改進其估計值,但是,反過來,若先決定 ![]() ,那麼因為
,那麼因為 ![]() 之分佈既與參數 σ 無關,那麼
之分佈既與參數 σ 無關,那麼 ![]() 之實際值對於 σ 參數的資訊而言,實在一點價值也沒有。所以對於參數 σ 之資訊,若想由
之實際值對於 σ 參數的資訊而言,實在一點價值也沒有。所以對於參數 σ 之資訊,若想由 ![]() 與
與 ![]() 得到,那麼它完全包括在
得到,那麼它完全包括在 ![]() 之中。而且若有其他估計量
之中。而且若有其他估計量 ![]() 用以代替
用以代替 ![]() ,則同樣情況仍然出現。因此,對於參數 σ 之所有資訊,完全包括在
,則同樣情況仍然出現。因此,對於參數 σ 之所有資訊,完全包括在 ![]() 之中。這些結果出現在1920年的論文中。
之中。這些結果出現在1920年的論文中。
費雪同時也發覺到,![]() 有這種性質與母體為常態分佈是互有關連的。當母體為雙指數分佈時,對於刻度參數 (scale parameter) 的估計,當 n 大時,費雪證明了
有這種性質與母體為常態分佈是互有關連的。當母體為雙指數分佈時,對於刻度參數 (scale parameter) 的估計,當 n 大時,費雪證明了 ![]() 比
比 ![]() 來得優越。在1922年的文章中,這種充分統計量的概念就完全清晰地刻畫了出來,他證明了所謂的「因子分解定理」(factorization theorem),就是說,若諸樣本隨機變數的聯合密度函數可分解成某統計量的密度函數與某一完全不含參數的函數之乘積,那麼該統計量必是該參數的充分統計量,反之,也然。在以後的統計理論發展過程中,充分統計量扮演一個重要的角色。
來得優越。在1922年的文章中,這種充分統計量的概念就完全清晰地刻畫了出來,他證明了所謂的「因子分解定理」(factorization theorem),就是說,若諸樣本隨機變數的聯合密度函數可分解成某統計量的密度函數與某一完全不含參數的函數之乘積,那麼該統計量必是該參數的充分統計量,反之,也然。在以後的統計理論發展過程中,充分統計量扮演一個重要的角色。
故事到此還不能結束,因為比費雪早一百多年,大數學家拉普拉斯 (P.S. de Laplace) 已作過了類似的研究。但這件事費雪似乎沒有注意到,因為在他的文章中,未提到拉氏的〈機率的解析理論第二增補篇〉(Deuxieme supplement a la Theorie Analytique des Probabilites)。這在1818年出版的增補篇裡,拉氏考慮了這樣一個問題(目前所謂的線性迴歸):
有 n 個聯立方程式
其中 pi,ai 為已知,y 與 xi 為未知,而 xi 表觀測時的差誤,問題是如何估計 y 值。
在早期的著作中,他已討論過最小平方法,當時他稱之為「最有利方法」,而在這增補篇他討論另一個方法,稱為「情況法」(method of situation)。這是1757年由波斯柯維區 (Boscovich) 首先介紹的。其實這個方法在拉氏1799年出版的《天體力學》一書中已經提到。方法是這樣的,找出某 y 值使下面(1)式值為最小,
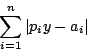 |
(1) |
拉式找出了這樣的解:
若
而 r 滿足
和
時,那麼
| (2) |
必使(1)值最小。若以 yMs 表(2)式值,而以 yLs 表最小平方解,那麼
拉氏假設觀測誤差 xi 值依密度函數 ![]() 而變化。設
而變化。設 ![]() 在零點可兩次微分,
在零點可兩次微分,![]() ,且對稱於 0。他進一步導出了 (yMs-y) 之極限分佈,為均值為 0。變異數為
,且對稱於 0。他進一步導出了 (yMs-y) 之極限分佈,為均值為 0。變異數為
之常態分佈。他也導出了 yLs 之極限分佈,而且發覺,假如而且只有
yMs 比 yLs 優越(極限變異數較小)。他也注意到了 ![]() 為常態時,yLs 比 yMs 理想。事實上可以說,拉氏是第一位將兩種理想的估計量作比較的人,他也是第一位導出有序統計量的極限分佈的人(pi=1,yMs 為中位數),他的方法可以由
為常態時,yLs 比 yMs 理想。事實上可以說,拉氏是第一位將兩種理想的估計量作比較的人,他也是第一位導出有序統計量的極限分佈的人(pi=1,yMs 為中位數),他的方法可以由 ![]() 擴展到不對稱的情形,比起費雪的方法更一般化了。拉氏到此也未停止,他又進一步導出了該兩個估計值的聯合分佈,他的目的是如何經由這兩個估計量 yMs 與 yLs 作出一個新的更理想的估計量。他用特徵函數的反轉 (inversion) 來表
擴展到不對稱的情形,比起費雪的方法更一般化了。拉氏到此也未停止,他又進一步導出了該兩個估計值的聯合分佈,他的目的是如何經由這兩個估計量 yMs 與 yLs 作出一個新的更理想的估計量。他用特徵函數的反轉 (inversion) 來表 ![]() 與
與 ![]() 分佈,然後以無窮級數將積分展開,取
分佈,然後以無窮級數將積分展開,取 ![]() ,得到
,得到 ![]() 之密度分佈為
之密度分佈為
![begin{displaymath}&10;Ccdotexp {frac{-1}{4k'}xi^2q-2k'frac{[2xiphi(0)-frac{kxi'}{k'}]^2}{4(k'-2k^2)}q }&10;end{displaymath}](http://episte.math.ntu.edu.tw/articles/mm/mm_03_3_08/img26.gif)
此處 C 為常數.
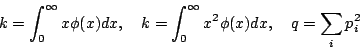
顯然,這就是均值為
互變異矩陣為
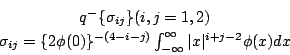
的二維常態分佈。利用這結果,他想找 α 使得
之極限變異數為最小,他算出其值為
![begin{displaymath}&10;alpha=frac{{2phi(0)[2phi(0)-frac{k}{k'}]}}{frac{1}{2k'}-(frac{k}{k'})^2+[2phi(0)-frac{k}{k'}]^2}&10;end{displaymath}](http://episte.math.ntu.edu.tw/articles/mm/mm_03_3_08/img31.gif)
所以只要
那麼 yLs 還可以改良,只要減去
當然,拉氏應該注意到只要 ![]() 與 e-kx2 成正比,則
與 e-kx2 成正比,則
這就是說,只要 ![]() 為常態分佈,那麼 yLs 不只比 yMs 為優越,而且 yLs 再也不能改良。也就是說,不可能經由 yLs 與 yMs 的線性組合作出更優異的估計量。他也因此意識到 yMs 與 yLs 之線性組合都不可能經由 yLs 增加對於 y 值的資訊。可惜,在這個方向上,若拉氏再跨出半步,或者他也早就得出了類似充分統計量的概念來。他的出發點以及運算都比費雪的更一般化,但是費雪能夠在具體的情況中抽離出較抽象而富普遍性的概念來。若說這需要一百年的時間才能作到,誰會相信。但,平心而論,在拉氏的年代裡,數理統計還在嬰兒時期,最小平方法的發現也只有十三年的歷史,什麼點估計,也不過是一片模糊的瞭解而已,而對於常態分佈這麼一個特殊而重要的分佈,他的特殊性質也還未為一般人所熟悉。反觀費雪時代,已經由皮爾遜 (K. Pearson) 及其他人的刻意經營,立下基礎,而一些統計概念也更為清晰,這或許說明了在不同的背景下,得到了不同的結果。但無論如何,這兩位大家以富於創意與精於摸索的心靈,所作出的貢獻是不可磨滅的。
為常態分佈,那麼 yLs 不只比 yMs 為優越,而且 yLs 再也不能改良。也就是說,不可能經由 yLs 與 yMs 的線性組合作出更優異的估計量。他也因此意識到 yMs 與 yLs 之線性組合都不可能經由 yLs 增加對於 y 值的資訊。可惜,在這個方向上,若拉氏再跨出半步,或者他也早就得出了類似充分統計量的概念來。他的出發點以及運算都比費雪的更一般化,但是費雪能夠在具體的情況中抽離出較抽象而富普遍性的概念來。若說這需要一百年的時間才能作到,誰會相信。但,平心而論,在拉氏的年代裡,數理統計還在嬰兒時期,最小平方法的發現也只有十三年的歷史,什麼點估計,也不過是一片模糊的瞭解而已,而對於常態分佈這麼一個特殊而重要的分佈,他的特殊性質也還未為一般人所熟悉。反觀費雪時代,已經由皮爾遜 (K. Pearson) 及其他人的刻意經營,立下基礎,而一些統計概念也更為清晰,這或許說明了在不同的背景下,得到了不同的結果。但無論如何,這兩位大家以富於創意與精於摸索的心靈,所作出的貢獻是不可磨滅的。
這樣一個統計學史上的故事,或許可以提供讀者一個印象,那就是對於一個具體的現象,或者數個看似無關的的個別現象,能夠抽離出或歸納出一個新的,更高層面的概念或體系,這種敏銳的洞察和歸納能力在科學工作上甚或思疇範圍內是及其重要且必須的,將原來的層面提升到更高的不同性質的層面,才在事物發展過程中具有進步的意義,然而這種提昇不可能憑空而來的,正如前所敘,經過皮爾遜等人工作的累積,才有費雪作抽象的提昇。拉氏在這方面的工作雖然展示了他那超越常人的蓬勃的創力才華,但是在向更高層面的突破跨越上,他並沒有成功,然而他的工作並非白費,他立下了很好的起點,導引了後人的提昇。

评论